AI Model Assessment and AI Persona
The assessment of LLM AI models cannot be straightforwardly determined by comparing their parameter sizes alone. It's crucial to delve into the internal software architecture and understand the limitations encountered when scaling up. These limitations are often dictated by the capabilities of accelerators such as GPUs or TPUs and their associated memory bandwidth. A smaller model, when ingeniously designed, can outperform a larger counterpart. The introduction of attention mechanisms in Transformers, for instance, has revolutionized concepts like RNNs and LSTMs. Similarly, the recent advancements in Mixture of Experts (MoE) have allowed for scaling up parameters in a way that dense models cannot match. This article aims to explore these nuances and provide insights for benchmarking among models. Additionally, the implementation of smart prompting configurations in Chatbot models can activate the AI's latent capabilities, creating a distinct AI persona that significantly enhances user interactions.

Introduction
The seminal paper "Attention is All You Need," presented in 2017, dramatically revolutionized the field of machine learning by introducing attention and self-attention mechanisms. This approach significantly improved upon the memory inefficiencies of previous RNN and LSTM architectures. Following this, OpenAI unveiled its groundbreaking LLM model, GPT-1, through the paper "Improving Language Understanding by Generative Pre-Training" in June 2018. GPT-1, a twelve-layer, decoder-only transformer model, featured twelve masked self-attention heads, each with 64-dimensional states, totaling 768 dimensions. It utilized the Adam optimization algorithm with a unique learning rate schedule, culminating in 117 million parameters.
In February 2019, OpenAI released GPT-2, boasting 1.5 billion parameters. It was pre-trained on the BookCorpus dataset, consisting of over 7,000 self-published fiction books across various genres, and further trained on a dataset of 8 million web pages. GPT-2 set new benchmarks, outperforming previous RNN/CNN/LSTM-based models.
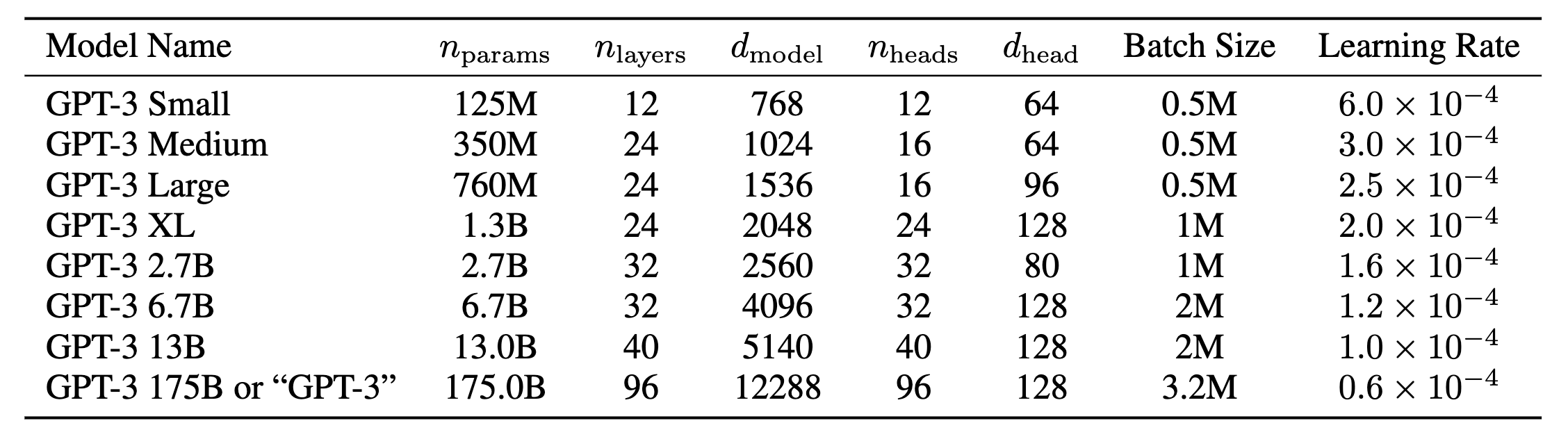 Various GPT-3 sizes and parameters, source from OpenAI's paper
Various GPT-3 sizes and parameters, source from OpenAI's paper
The introduction of GPT-3 in 2020 marked another milestone, with models ranging from 125 million to 175 billion parameters. GPT-3 featured a mix of dense and sparse attention mechanisms, trained on datasets encompassing 500 billion tokens. While the specifics of GPT-3.5, released on November 30, 2022, remain undisclosed due to its closed-source nature, it was initially known as text-davinci-003 before being announced as the "GPT-3.5 series."
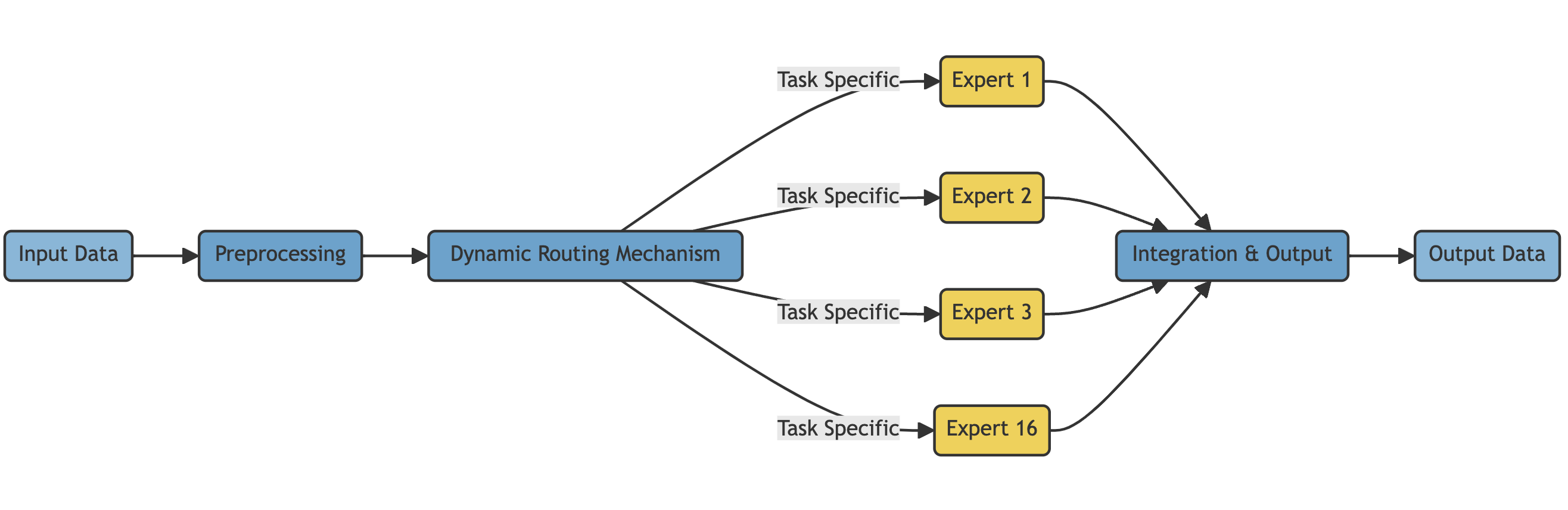 Mixture of Experts (MoE) architecture
Mixture of Experts (MoE) architecture
GPT-4, released on March 14, 2023, incorporated a Mixture of Experts (MoE) architecture with 16 subunit expert models, each containing approximately 111 billion parameters for the MLP. A typical forward pass involves routing to two of these experts, combining for approximately 1.8 trillion parameters across 120 layers, with about 55 billion shared parameters for attention. Remarkably, each token generation only utilizes around 280 billion parameters and 560 TFLOPs, in contrast to the 1.8 trillion parameters and 3,700 TFLOPs a purely dense model would require. OpenAI trained GPT-4 on approximately 13 trillion tokens, encompassing multiple epochs due to a scarcity of high-quality tokens. Despite the challenges of low utilization rates and the need for frequent restarts from checkpoints due to failures, GPT-4 represents a significant advancement, achieving unparalleled performance in the LLM field. Researchers have found that using 64 to 128 experts can yield better loss than 16 experts, yet there are pragmatic reasons for opting for fewer experts, including generalization challenges across various tasks. Today, GPT-4 stands as the industry's leading model, surpassing the "standard" benchmark previously set by GPT-3.5.
The Battle Between Sparse vs. Dense Models
With GPT-3.5 setting the industrial benchmark, five companies besides OpenAI have developed models surpassing GPT-3.5 across various benchmarks: Mistral's Mixtral, Inflection's Inflection-2/Pi, Anthropic's Claude 2, Google's Gemini Pro, and X.AI's Grok. Remarkably, Mistral and X.AI achieved these results with teams of fewer than 20 people. Additionally, we anticipate that Amazon, Meta, Databricks, 01.AI (Yi), Baidu, and Bytedance will soon exceed GPT-3.5 performance. It's intriguing and somewhat self-evident that open-source models, constrained by "limited GPT resources" in pre-training or inference, struggle to keep pace with these enterprise-grade LLMs. Without Meta's release of LLaMa and LLaMa2 (7b - 170b parameters), surpassing the colossal GPT-4, with its 1.8 trillion parameters, would be challenging.
Which one do you think wins?
— Alvaro Cintas (@dr_cintas) February 10, 2024
Google's Gemini emerges as OpenAI's most formidable competitor. Google's contributions to the NLP community, such as TensorFlow, Transformer, and MoE, are well-regarded. However, OpenAI caught Google off guard with the successful launch of ChatGPT based on GPT-3.5, achieving 1 million users in 5 days, 100 million in a month, and 1 billion in two months, surpassing Google's internal threshold for success of 200 million users. Since then, Google has leveraged its comprehensive AI strategy to compete with OpenAI and its strategic partner, Microsoft.
Google introduced early access to Bard, powered initially by LaMDA and later by PaLM, on March 21, 2023. Recognizing its position behind OpenAI, Google combined efforts from Google Brain and DeepMind to announce its flagship LLM, Gemini. On February 8, 2024, Bard and Duet AI were unified under the Gemini brand, launching a mobile app for Android and integrating the service into the Google app on iOS. Android users saw Gemini replace Assistant as the default virtual assistant, though Assistant remained available. Google also unveiled "Gemini Advanced with Ultra 1.0" through a "Google One AI Premium" subscription, reaching 200 million users.
The advent of Gemini, with models ranging from the nano (1.8 billion and 3.25 billion parameters) to the pro (estimated 100-200 billion parameters) and Ultra (expected 500 billion parameters) models, including the MoE-based Pro 1.5 (expected 1.5 trillion parameters), complicates the market assessment of LLM models. The distinction between dense models (like Ultra 1.0) and sparse models (like GPT-4) confuses many. Benchmarking sites that rely on human assessment have controversially included Bard, which we disagree with, as it compares fundamentally different models (Bard, being a chatbot website, should be directly compared with ChatGPT). We propose the series numbering VE (vertical enhancement for core dense models) and HE (horizontal enhancement for sparse MoE models), such as VE.HE (e.g., 1.0 and 1.5), to systematically categorize models. In the latter part of this article, we will also compare various tasks, including multimodal models. For several models comparable to GPT-4 that do not disclose technical details like parameter size, we will rely on meta-analysis and open-source intelligence for assessment.
Scaling Law in AI Development
In the development of Generative AI, such as GPT-4 or Gemini Ultra 1.0, the process involves several steps: sourcing datasets for pre-training, fine-tuning the model with more specific datasets, and possibly implementing another round of refinements to enhance human interaction capabilities. Throughout these stages, various decisions must be made, including the model's parameter size, the dataset size for training, and the number of epochs required to reach the inflection point. Navigating these options reveals a nearly limitless array of approaches to constructing Generative AI. Understanding the scaling laws is critical for optimizing the model's state-of-the-art (SoA) performance for specific tasks.
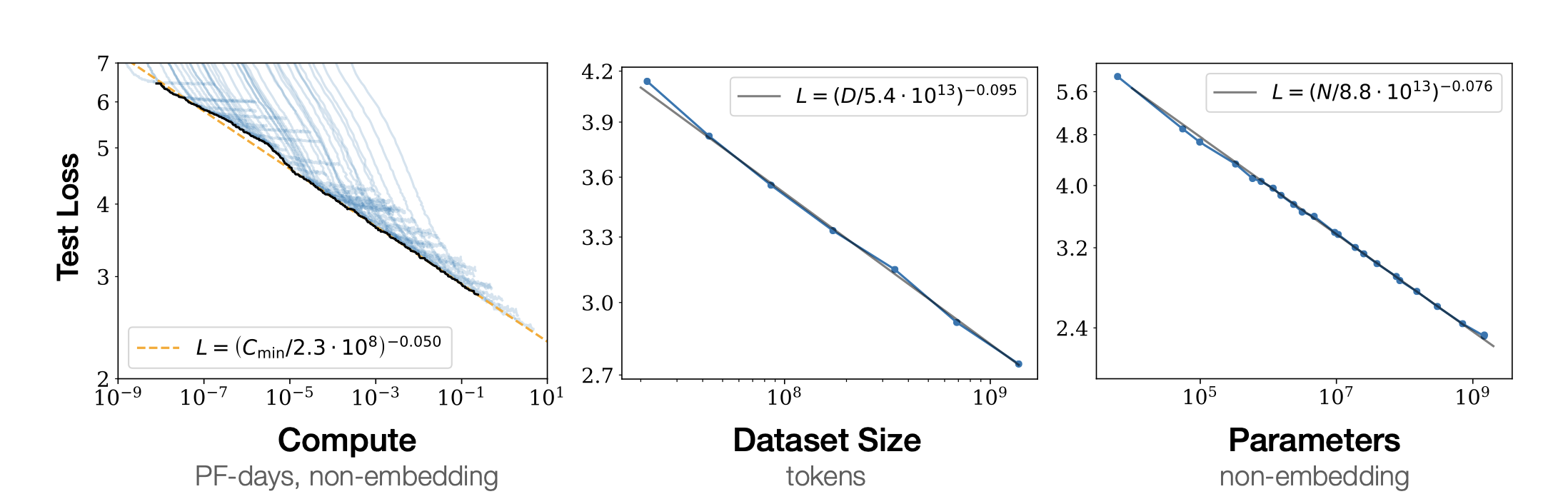 Computational power, dataset size and model parameter size must be increased altogether to avoid diminishing return
Computational power, dataset size and model parameter size must be increased altogether to avoid diminishing return
Kaplan et al. (2020) shed light on the complex relationship between an AI model's scale and its performance. They found that performance significantly correlates with the scale of computation (C), data (D), and the number of parameters (N), particularly when these factors are not limiting. Their research highlights the importance of scaling N and D together to improve performance without encountering diminishing returns. The ability to predict training outcomes early on provides insight into future performance, including accuracy with out-of-distribution (OOD) data. Larger models demonstrate better sample efficiency than smaller ones, despite slower convergence. Furthermore, they suggest that optimal batch size varies with the model's loss power, indicating a nuanced approach to scaling is necessary for peak performance.
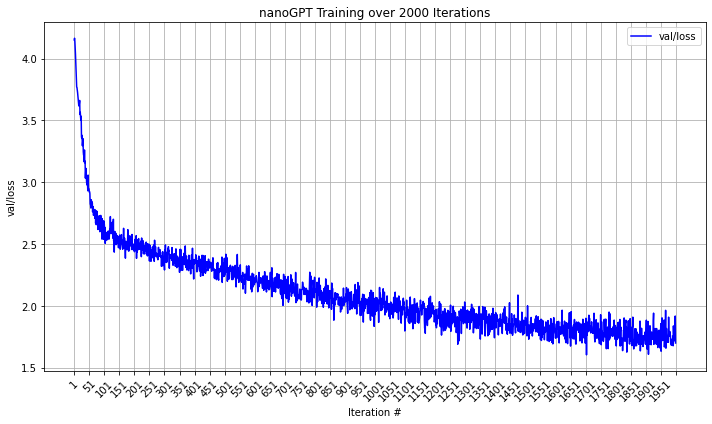 nanoGPT, trained over 2,000 epochs, illustrates the application of scaling law in practice.
nanoGPT, trained over 2,000 epochs, illustrates the application of scaling law in practice.
Scaling up a model is feasible as long as computational resources, parameter count, and data volume can grow, especially if data volume is at least five times greater than the parameter count. Conversely, Ronen Eldan and Yuanzhi Li (2023) introduced TinyStories, a compact dataset for training smaller models, demonstrating that a model with as few as 30 million parameters can generate coherent English text. This suggests that with well-curated data, smaller models can be effectively operated on standard computers. Our experiments with nanoGPT, a smaller version of GPT-2 trained on Shakespeare's works for 2,000 epochs, achieved a validation loss of 1.6982. This supports the identified scaling laws, highlighting a 'Goldilocks Zone' for model size, ranging from as small as 30 million parameters to as large as GPT-4's 1.8 trillion parameters, including models utilizing sparse MoE architecture.
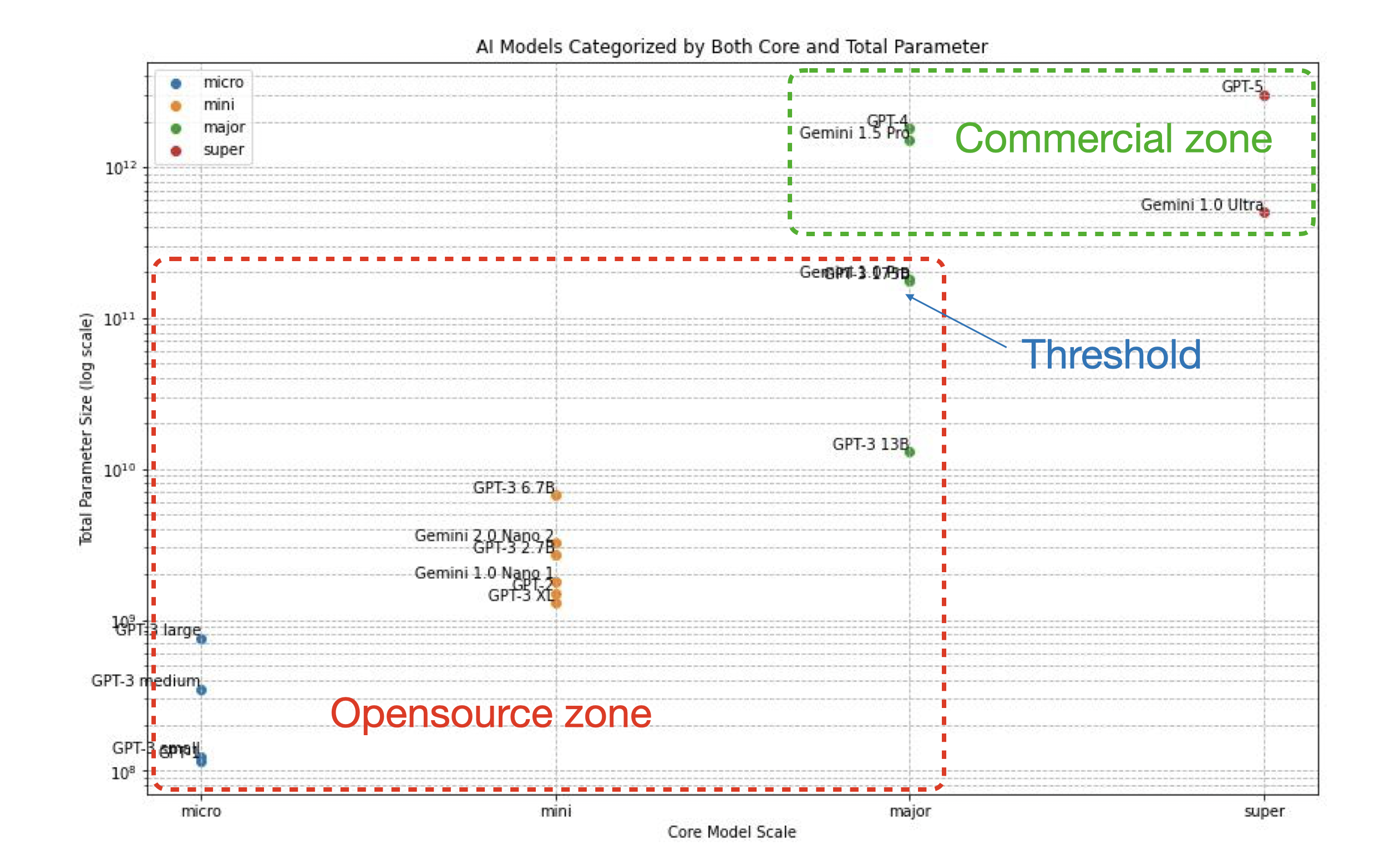 Models categorize by both core dense parameters and total parameters.
Models categorize by both core dense parameters and total parameters.
As Google's Chief Scientific Officer, Jeff Dean, elucidated in a tweet emphasized the genesis of Gemini, a project that combines the prowess of Google's Brain team (with its PaLM/PaLM-2 models) and DeepMind's Chinchilla, aiming to forge an innovative multimodal model. The inaugural version of PaLM, launched in October 2022, showcased varying scales, including 8 billion, 62 billion, and a colossal 540 billion parameters. Its publication boasts superior performance over Chinchilla, a 70B parameter model trained on 1.4 trillion tokens, with PaLM's 62 billion parameter model outperforming GPT-3's largest 175 billion parameter scale. PaLM's pretraining dataset, comprising a meticulously curated 780 billion tokens, spans a broad spectrum of linguistic scenarios, positioning PaLM as a leading contender in multilingual large language models (LLMs). The significant edge PaLM holds over Chinchilla underscores the impact of dataset optimization over sheer model size. DeepMind's research with Chinchilla illuminated the efficacy of leveraging a well-curated dataset, even with fewer parameters, to surpass models with larger parameters. By assimilating this insight, PaLM not only surpassed Chinchilla but also refined dataset optimization techniques. (The Chinchilla outperformed DeepMind's previous Gopher model, a 280-billion-parameter model trained on the MassiveText dataset which contains 2.35 billion documents, or approximately 10.5 TB of text.)
 The Chinchilla paper presents estimated optimal training FLOPs and training tokens for various dense model sizes, ranging from 400 million parameters to 10 trillion parameters. This table includes the largest model currently known.
The Chinchilla paper presents estimated optimal training FLOPs and training tokens for various dense model sizes, ranging from 400 million parameters to 10 trillion parameters. This table includes the largest model currently known.
The goal of Gemini, encompassing versions 1.0 Pro, 1.0 Ultra, and especially the sparse MoE model of 1.5 Pro, extends beyond integrating dataset utilization strategies observed in DeepMind's Chinchilla and achieving the state of excellence in multilingual large models like PaLM/PaLM2. It aspires to realize true multilingual/multimodal AI capabilities, enabling the model to process inputs from diverse media types—text, video, voice, and images—and generate outputs in both text and image formats. Gemini has been trained on a comprehensive multimodal dataset, granting it the ability to understand various media forms thoroughly. Moreover, with an expanded context space of up to 1 million tokens and minimal loss upon retrieval—akin to precisely finding "a needle in a haystack"—Gemini aims to surpass the capabilities of OpenAI's GPT-4 effortlessly. Now that API access to both Gemini 1.0 Pro and 1.5 Pro is available, we plan to conduct a comparative study against GPT-4, focusing on task performance. Additionally, on the platform, we will compare Gemini 1.0 Ultra on the Gemini Advanced platform directly against ChatGPT Pro powered by GPT-4, through both meta-analysis and qualitative analysis.
Model Evaluation Techniques
Although LMsys has published its benchmarking study utilizing an online platform's human evaluations, showcasing impressive results akin to A/B testing, we identify disagreements on two fronts. First, the inclusion of Bard as a platform rather than a model is problematic; it should be juxtaposed with platforms like ChatGPT, not models. Second, the methodology conflates blind testing with open testing. While the rationale behind offering users free access to the models for benchmarking purposes is understandable, opting for open testing over blind testing introduces the risk of bias. Such bias stems from users' preconceived preferences, influenced by the model's reputation or their own experience, potentially skewing the results.
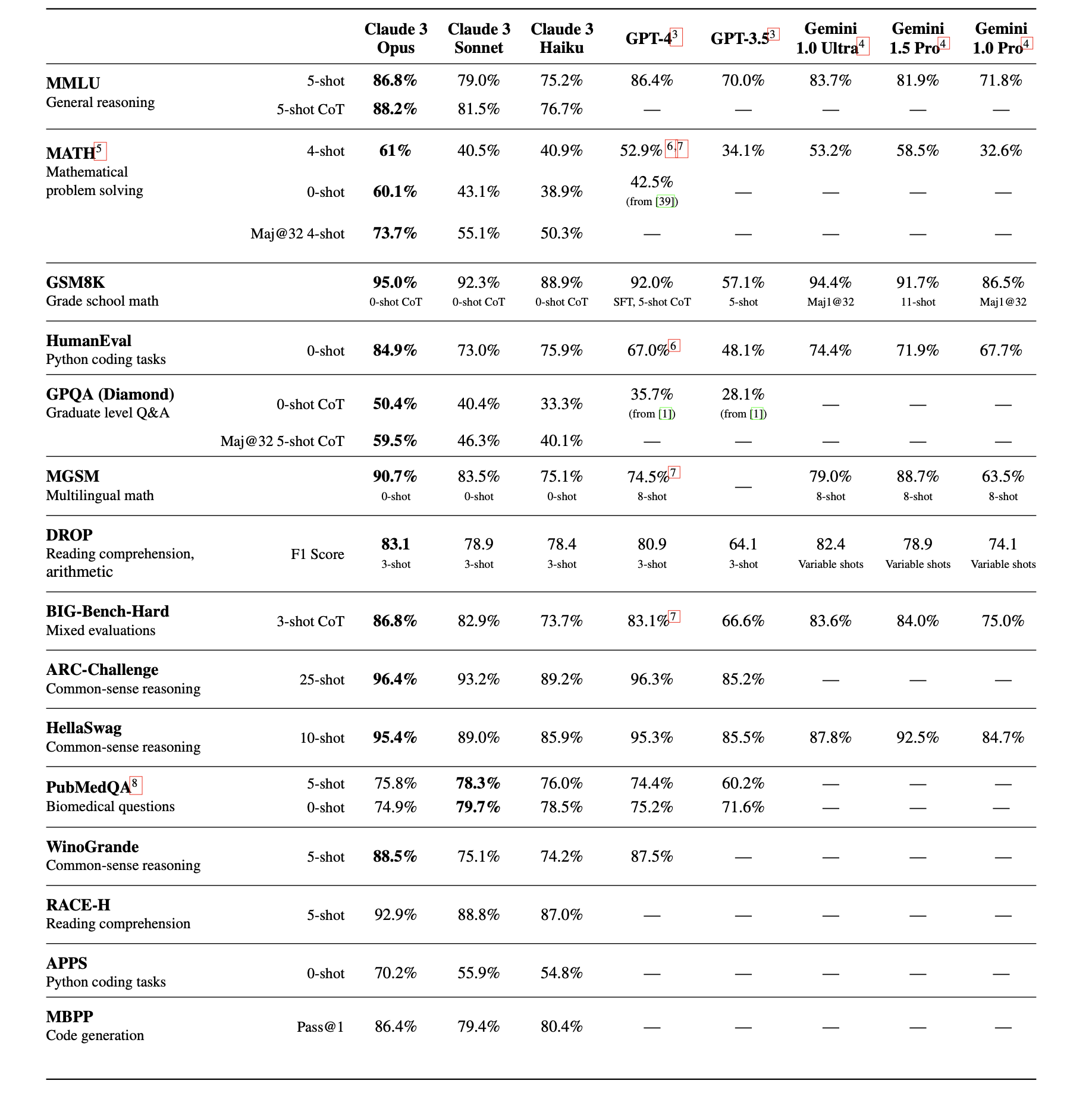 Anthropic has provideds comparative benchmarking against major model which are Claude 3.0, OpenAI's GPT-4 and Google's Gemini
Anthropic has provideds comparative benchmarking against major model which are Claude 3.0, OpenAI's GPT-4 and Google's Gemini
However, the paper accurately classifies the current benchmarking frameworks into four categories using two criteria: a) ground truth versus human preference, and b) static/finite questions versus live/improvisational questioning. Thus, we identify four benchmarking paradigms: 1) Static & Ground Truth, exemplified by benchmarks like MMLU, HellaSwag, and GSM-8K; 2) Static & Human Preference, represented by MT-Bench and AlpacaEval; 3) Live & Ground Truth, as seen in Codeforces Weekly Contests; and 4) Live & Human Preference, demonstrated by the LMsys chatbot arena. Claude's document adeptly clarifies the first paradigm, detailing how to address potential flaws during model benchmarking. Building on this, we propose a novel fifth paradigm that mirrors human examination methods. This approach involves presenting clear, logical problems for the model to solve. These problems are verifiable and testable, akin to coding challenges where a successful execution indicates the model's proficiency. To ensure the integrity of this testing, we introduce novel mathematical concepts like nested matrices, specifically designed to circumvent the model's prior training data exposure, thereby offering a fresh and unexploited benchmarking landscape.
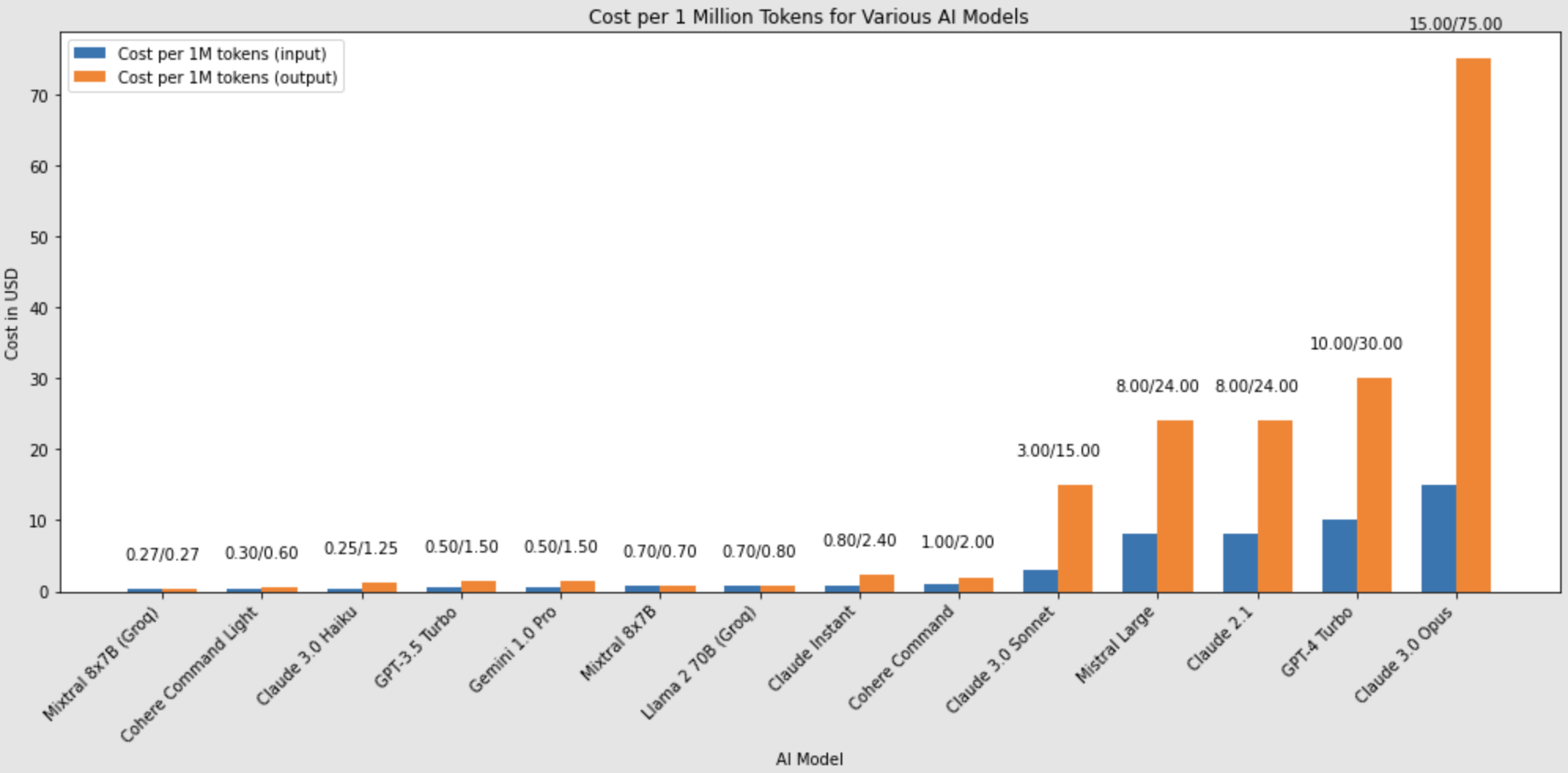 Comparative pricing among key available models in the market. Other real time comparative study can be found at Artificial Analysis.
Comparative pricing among key available models in the market. Other real time comparative study can be found at Artificial Analysis.
Our test results corroborate Anthropic's findings, revealing that Claude 3.0's largest variant, the Opus, excels in areas like coding. However, GPT-4 remains the most reliable model for our purposes to date. Meanwhile, the Gemini model, despite its linguistic prowess and impressive context window size, falls behind the other two in comparison. This observation aligns with our distinction between "open source" and "commercial" models. It indicates that while smaller models (with 100-900 million parameters) to mid-range models (around 70 billion parameters) can operate on local GPUs in resource-constrained environments, deploying colossal models such as Claude Opus, GPT-4, and Gemini necessitates substantial GPU resources and a large user base to achieve economies of scale, as previously outlined in our chart. Additionally, the higher cost associated with the Opus model, as shown in Anthropic's pricing chart, aligns with our benchmarking outcomes. The question remains: why does Gemini, despite Google's robust research efforts, not perform as well as its counterparts? We will delve into this matter in the subsequent section.
TBC / TDK