Adaptive Intelligence Framework
The Adaptive Intelligence Framework (AIF) is a novel approach for understanding and comparing the learning and adaptation processes in both biological and artificial neural networks.

Key Concept
Contrary to mainstream belief, people often argue that AI systems are incapable of truly understanding reality, dismissing their outputs as "hallucinations." Yet, it's crucial to recognize that humans, too, can perceive reality in biased or distorted ways. Our understanding of the cosmos evolved from the Kepler system to Galileo's revelations, and our worldview transformed from a flat earth to a spherical globe. This evolution in thought highlights a key point: both humans and AI craft their "represented knowledge" based on their perception and interpretation of reality. The Adaptive Intelligence Framework (AIF) aims to equally evaluate how this knowledge is formed, whether in human minds or AI systems.
Central to understanding the AIF is an insightful equation:
$$\text{K} \approx f(\text{g(D, M)}, \text{R})$$
Knowledge (K) is formed through a process function (f) that combines and processes input data (D), a subset or representation of external reality (R) directly interacted with or observed, and cognitive architecture (M), which includes the mental or algorithmic structures and processes used to interpret this data, all of which are evaluated against the external reality (R) as a reference point or ground truth.
Normally, as the more established knowledge handler, humans often initiate inquiries and recheck responses from AI through prompting, given their role as creators. AI, having encapsulated a wide range of knowledge through pre-training and fine-tuning, is adept at generating optimal text responses to human users. It is crucial for the user, preferably an expert in the relevant field, to provide reliable ground truth for verifying the AI's output. Humans can also utilize their sensory data input to validate the AI's responses, as the AI relies on input data extracted from external reality, leading it to have a meta-causal representation of reality rather than a direct understanding of it. Therefore, it is always imperative to verify AI outputs against available ground truths to ensure accuracy and reliability.
Multiple Iteration Technique
In the iterative interaction between humans and AI, particularly in the context of Large Language Models (LLMs), the exchange of knowledge can be conceptualized using the foundational equation discussed earlier. This process begins with a human user, typically more knowledgeable in a specific domain, initiating the interaction by posing an inquiry to the AI. This inquiry forms part of the input data (D), which the AI processes through its cognitive architecture (M), resulting in a response that is a meta-causal representation of reality.
 Human and AI interactions often involve several iterations to converge on the optimal solution for a given problem. This verification process encompasses various modes of inquiry. For instance, a human might ask the AI to write code to solve a problem, provide a mathematical equation, or create a Graphviz dot code diagram, among other requests. These interactions serve to align the perceived understanding of reality between the human and the AI, ensuring they are in sync and effectively addressing the problem at hand.
Human and AI interactions often involve several iterations to converge on the optimal solution for a given problem. This verification process encompasses various modes of inquiry. For instance, a human might ask the AI to write code to solve a problem, provide a mathematical equation, or create a Graphviz dot code diagram, among other requests. These interactions serve to align the perceived understanding of reality between the human and the AI, ensuring they are in sync and effectively addressing the problem at hand.
The user then evaluates the AI's response against their own knowledge (K-human), sensory inputs, and available ground truth (R). This evaluation often involves comparing the AI's output with established facts or real-world data to verify its accuracy. Based on this assessment, the human provides feedback to the AI, contributing to a refined set of input data (D).
With each iteration, the AI updates its response considering the new input data (D) and the continuous adaptation of its cognitive architecture (M). This iterative cycle leads to a refined interaction:
$$ \sum_{i=0}^{t} I^{i} = \sum_{i=0}^{t} f(K_{\text{human}}^{i}, K_{\text{AI}}^{i}) $$
where both the human's and the AI's knowledge states become more aligned and enhanced.
Through multiple iterations, the knowledge states of both the human and the AI undergo a process of refinement and alignment. The AI's responses become increasingly accurate and relevant, while the human user gains a deeper understanding or confirmation of the subject matter. This iterative process aims for a convergence where both human's knowledge and AI's knowledge are enriched, leading to a comprehensive and mutually beneficial exchange of knowledge.
AI Hallucination Reduction Technique
Building upon our knowledge representation equation, it becomes evident that a well-curated, reality-aligned dataset is crucial for both humans and AI to accurately understand and represent knowledge. This understanding leads us to several techniques aimed at reducing AI hallucinations, each aligning with our equation's principles to enhance the AI's precision and grounding in reality.
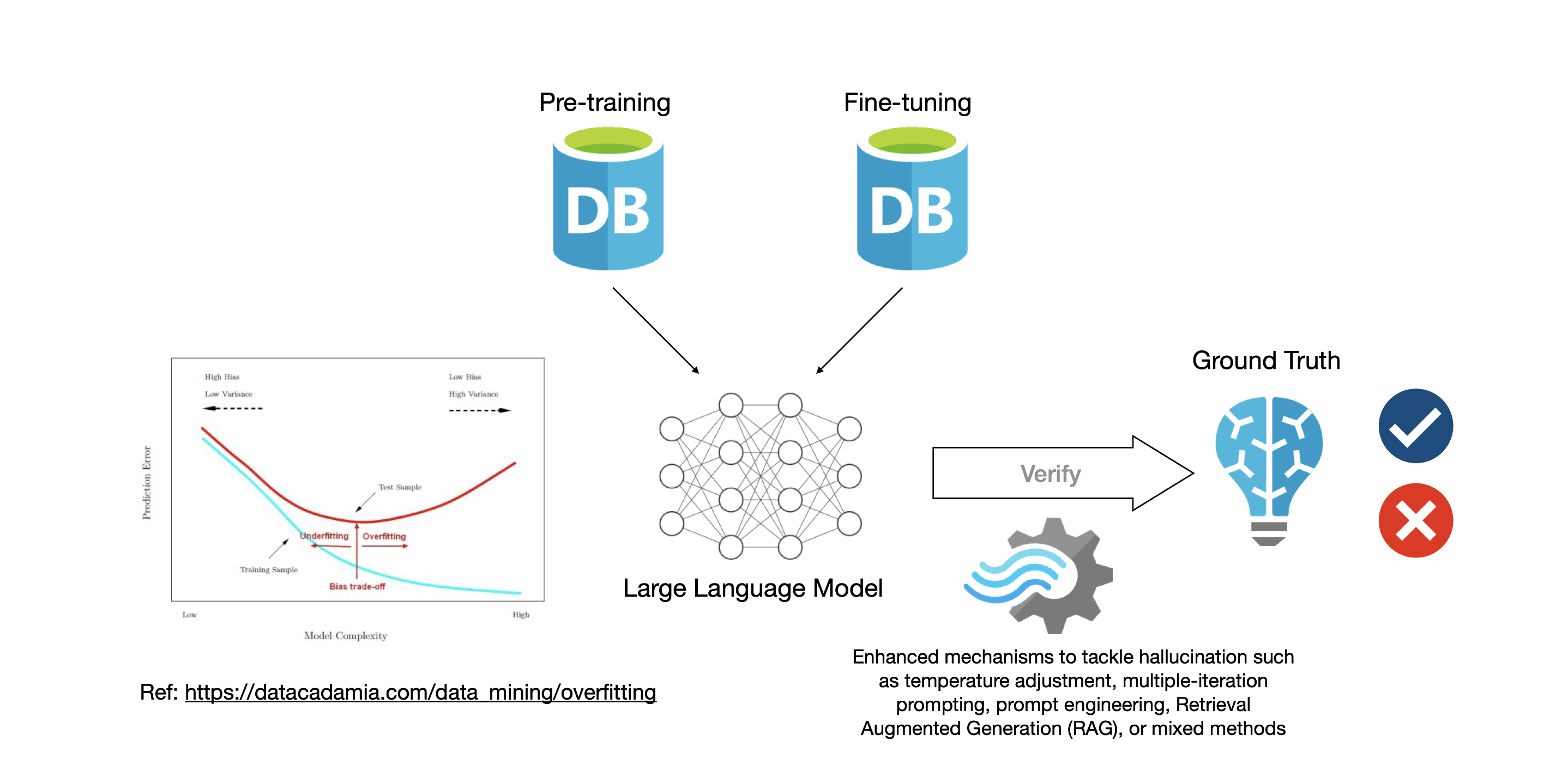 Utilizing temperature settings in AI language models to reduce hallucinations addresses only surface-level response characteristics without ensuring factual accuracy or alignment with external reality, and lacks the contextual depth and quality enhancement of input data, making it less effective compared to methods that focus on improving data quality (D), refining cognitive architecture (M), and incorporating expert feedback, essential for accurate, reliable, and reality-aligned AI outputs. Setting the AI's temperature to a lower level, which limits its "imagination," is generally not ideal for creative tasks such as scenario planning, future studies, or fiction writing. Such tasks often benefit from a higher degree of creativity and novelty in responses, which a lower temperature setting might not adequately provide.
Utilizing temperature settings in AI language models to reduce hallucinations addresses only surface-level response characteristics without ensuring factual accuracy or alignment with external reality, and lacks the contextual depth and quality enhancement of input data, making it less effective compared to methods that focus on improving data quality (D), refining cognitive architecture (M), and incorporating expert feedback, essential for accurate, reliable, and reality-aligned AI outputs. Setting the AI's temperature to a lower level, which limits its "imagination," is generally not ideal for creative tasks such as scenario planning, future studies, or fiction writing. Such tasks often benefit from a higher degree of creativity and novelty in responses, which a lower temperature setting might not adequately provide.
Firstly, adding reliable sources via a vector database directly enhances the quality of the input data (D) used by the AI. This approach involves integrating data from verified and authoritative sources into the AI's training regime. By doing so, we improve the AI's interpretation function (g(D, M)), ensuring that its responses are more accurately aligned with the external reality (R). This technique mitigates the risk of misinformation, grounding the AI's responses in verified knowledge.
Secondly, acquiring up-to-date news and social media content keeps the AI's knowledge base current and reflective of the ongoing changes in the external reality. Regularly updating the AI with recent information ensures that its data input (D) remains relevant, reducing the gap between its knowledge representation and the dynamic, real-world developments. This continuous updating process ensures that the AI stays informed about latest events and societal trends, enhancing its ability to provide timely and contextually relevant responses.
The third technique involves using multiple AI systems to crosscheck each other. This method introduces a system of checks and balances, where each AI system contributes its interpretation of the data and cognitive architecture (M). Cross-verification among different AI systems helps identify errors or biases in individual AI responses. By having multiple AIs compare and contrast their outputs, we can achieve a more balanced and accurate representation of knowledge, further reducing the likelihood of hallucinations.
Finally, fine-tuning the AI on specific topics tailors its cognitive architecture (M) and data processing capabilities to those areas. This focused approach enhances the AI's expertise in particular domains, making its responses in those fields more reliable and reducing the chances of inaccurate or irrelevant information. Fine-tuning allows for deeper and more nuanced understanding within specific contexts, aligning the AI's knowledge representation closely with the intricacies of those subjects.
Prompt Engineering (A) refines AI output through precise instructions, Temperature Setting (B) strikes a balance between creativity and factuality, Verification with Multiple AIs (C) cross-checks results for accuracy, Verification with Credible Online Sources (D) utilizes automated cross-checking with trusted databases like Pinecone for up-to-date information, and Fine-Tuning (E) leverages specific data to boost AI accuracy in targeted domains.
The Power of Prompt Engineering in AI
When navigating the intricate landscape of LLMs, it's critical to recognize the parallels between their memory mechanisms and human memory. Just as humans rely on a complex network of weighted neurons, LLMs such as those developed by OpenAI operate on a comparable principle. These networks, arranged and refined during pre-training and fine-tuning phases, bear resemblance to what we might call "permanent memory." Techniques like LoRA (Low-Rank Adaptation) play a role in fine-tuning, making certain parts of the network more adaptable, though within the confines of limited memory space.
Pressure Testing GPT-4-128K With Long Context Recall
— Greg Kamradt (@GregKamradt) November 8, 2023
128K tokens of context is awesome - but what's performance like?
I wanted to find out so I did a “needle in a haystack” analysis
Some expected (and unexpected) results
Here's what I found:
Findings:
* GPT-4’s recall… pic.twitter.com/nHMokmfhW5
OpenAI's GPT-4 Turbo represents a significant leap in this arena. Its ability to handle an expanded context space of up to 128K tokens is akin to embedding the contents of a 200-page book within its neural pathways. This enhancement allows for more extensive data processing and idea generation within a single interaction, opening new avenues for more complex and nuanced conversations.
However, to transcend the limitations of inbuilt memory, techniques like Retrieval-Augmented Generation (RAG) come into play. RAG essentially involves vectorizing data and storing it in vector databases such as Pinecone or Chroma. This method allows for the storage and retrieval of vast amounts of information, far exceeding the model's native capacity. The retrieval process, typically utilizing techniques like K-Nearest Neighbors (KNN), isn't as seamless as the memory recall in LLMs, but it compensates by providing access to a substantially larger information reservoir.
The RAG technique can be broken down as follows:
1. Net-Related RAG:
1.1 Direct Web Crawling: This approach involves actively searching the internet to gather real-time data, analogous to sending out digital scouts to collect information.
1.2 Preparing and Storing Data: Here, the focus is on organizing and storing the collected data in vector databases, ensuring it's readily accessible for future retrievals.
2. Document-Related RAG:
2.1 Tokenized Whole Document: This method involves breaking down entire documents into tokens that can be processed within the model's context window, allowing for a deep dive into specific texts.
2.2 Vectorized Whole Document: By converting entire documents into vectors and storing them separately, this technique facilitates a broader, though sometimes less precise, understanding of large volumes of text.
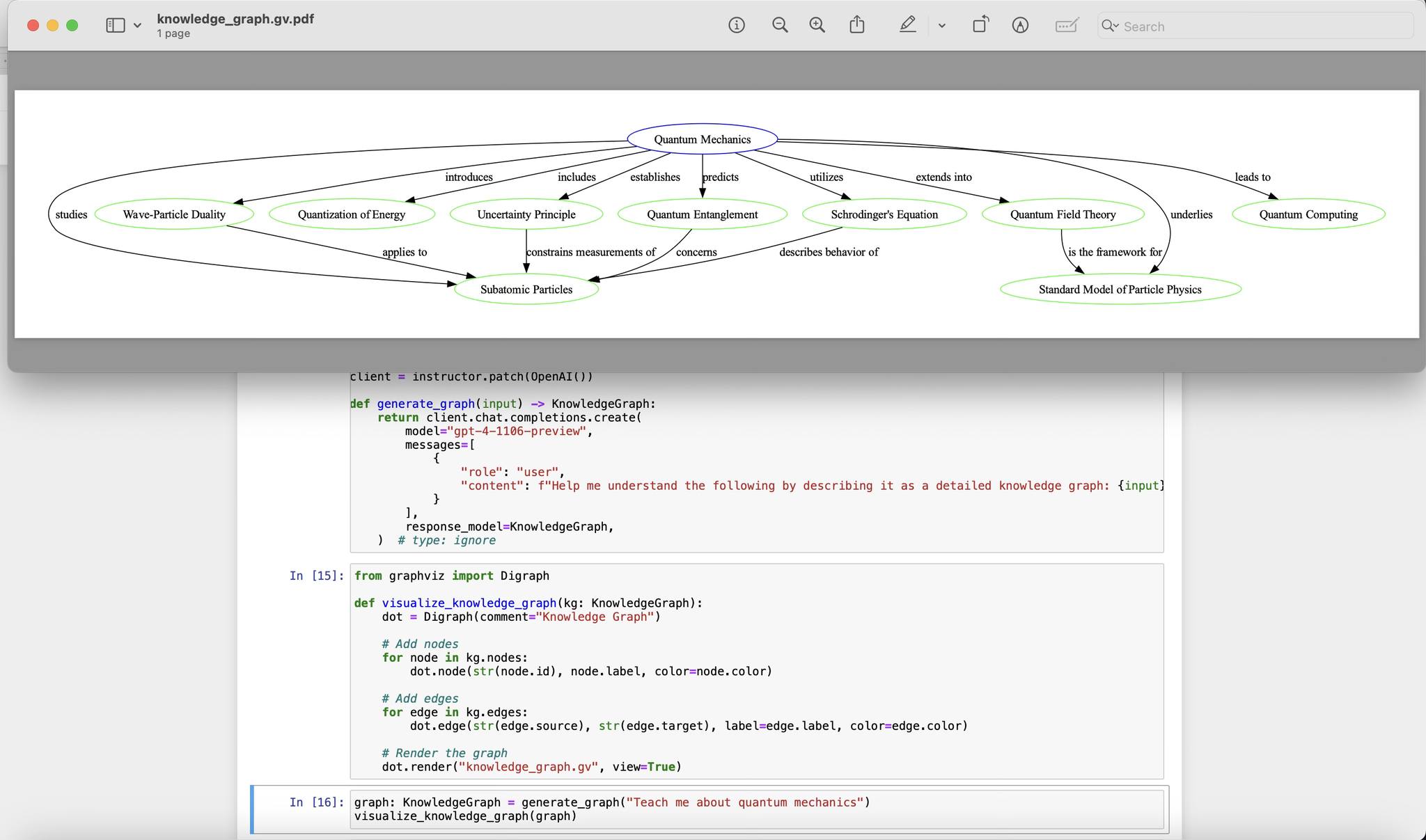 Here is what a 'knowledge graph'looks like. We can create it using Python libraries or the Graphviz application. In its simplest form, it can be presented as a bulleted list. This approach is advantageous because, instead of inputting an entire document, it provides the LLM with relationships and relevant keywords. This allows for better synchronization with the LLM's existing weighted neural networks.
Here is what a 'knowledge graph'looks like. We can create it using Python libraries or the Graphviz application. In its simplest form, it can be presented as a bulleted list. This approach is advantageous because, instead of inputting an entire document, it provides the LLM with relationships and relevant keywords. This allows for better synchronization with the LLM's existing weighted neural networks.
Prompt Engineering, or in-context prompting, becomes instrumental here by integrating the knowledge derived from multiple iteration inquiries between humans and AI, as outlined in the AIF equation above. Utilizing techniques like Chain of Thought (CoT), see for an example here, or zero-shot and few-shot prompting, we can effectively guide the LLM in processing and understanding complex inquiries. Furthermore, structuring information into a knowledge graph can significantly enhance the LLM's ability to digest and interpret the data. This synthesis of advanced prompting techniques and structured knowledge representation elevates the capabilities and precision of LLMs, enabling them to produce more accurate and insightful responses.
Conclusion
For highly sensitive use cases, where accuracy and precision are paramount, such as in healthcare, finance, or geopolitical risk analysis, it is crucial to employ a comprehensive approach. This includes integrating various techniques like prompt engineering, Retrieval-Augmented Generation (RAG), fine-tuning, and the use of knowledge graphs. In our application of AI for portfolio investment and exploiting geopolitical risk analysis, we've experimented with combining internet social media and news scanning with RAG, using databases like Pinecone in our Pulsarwave system. Following the insights from Microsoft's research paper, we've seen that leveraging prompt engineering and RAG with OpenAI's GPT-4 can outperform Google's PaLM2 and its fine-tuned variant, Med-PaLM 2.
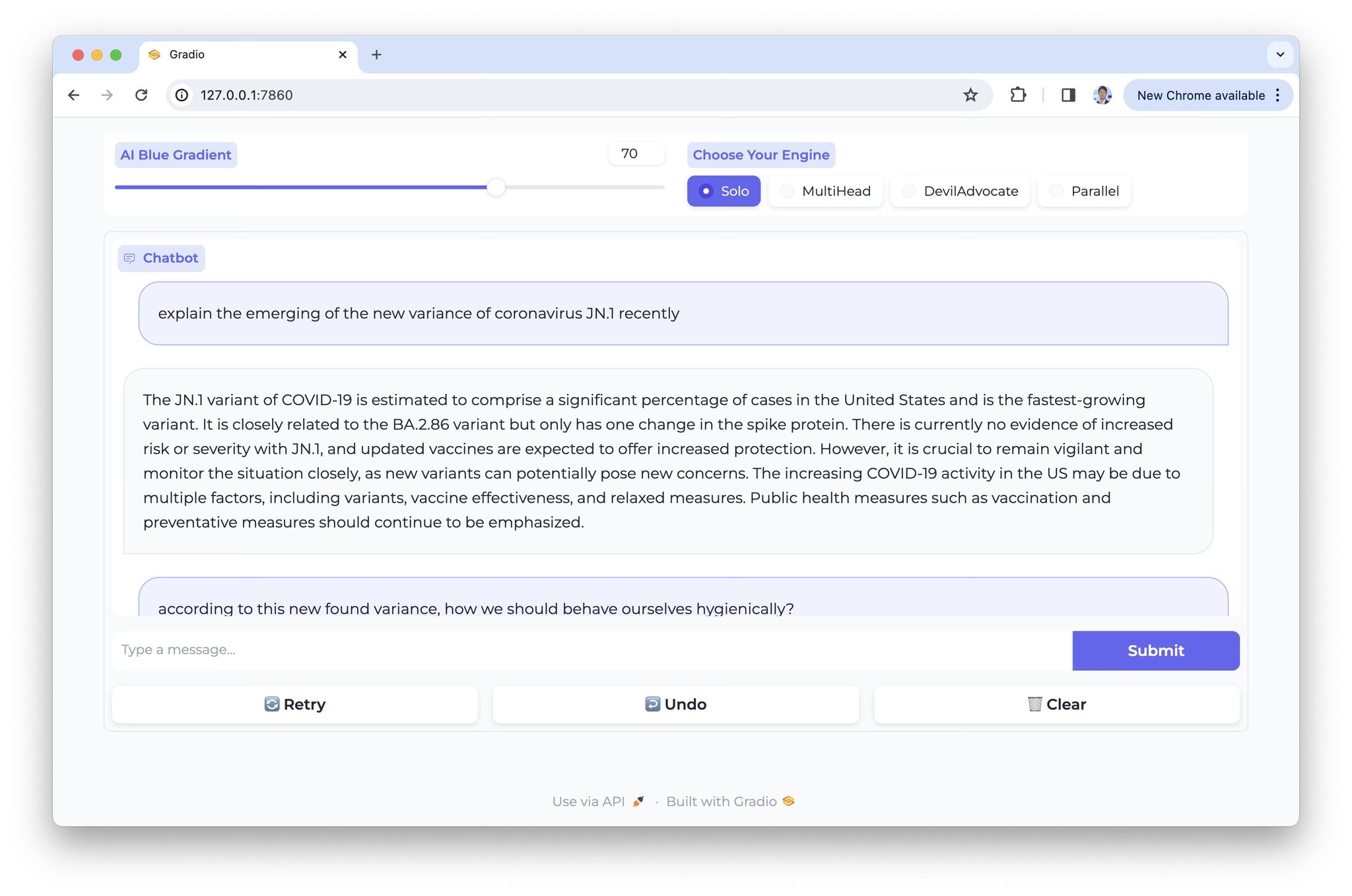 In our recent experiment, AI Blue effectively employed Retrieval-Augmented Generation (RAG) and multi-headed AI techniques to assimilate and accurately interpret information about the JN.1 coronavirus variant. This achievement was grounded in insights derived from two key research papers: "Fast evolution of SARS-CoV-2 BA.2.86 to JN.1 under heavy immune pressure" and Virological characteristics of the SARS-CoV-2 JN.1 variant." These studies provided the essential 'ground truth' that enabled AI Blue to integrate cutting-edge scientific knowledge into its analytical framework, demonstrating the power of advanced AI techniques in synthesizing complex biological data.
In our recent experiment, AI Blue effectively employed Retrieval-Augmented Generation (RAG) and multi-headed AI techniques to assimilate and accurately interpret information about the JN.1 coronavirus variant. This achievement was grounded in insights derived from two key research papers: "Fast evolution of SARS-CoV-2 BA.2.86 to JN.1 under heavy immune pressure" and Virological characteristics of the SARS-CoV-2 JN.1 variant." These studies provided the essential 'ground truth' that enabled AI Blue to integrate cutting-edge scientific knowledge into its analytical framework, demonstrating the power of advanced AI techniques in synthesizing complex biological data.
However, the trend suggests that simply increasing the size of LLMs and incorporating more data may be approaching a point of diminishing returns. Smaller LLMs utilizing a Mixture of Experts (MoE) model, acting as sub-unit LLM routers, might yield better results, as evidenced in the Mixtral project. Our experiments with AI Blue, which integrates sub-units of AI from OpenAI's GPT, Google's Gemini, and Mistral AI's Mistral, have shown promising outcomes. AI Blue, for instance, was able to accurately inform users about the JN.1 (BA.2.86.1.1) coronavirus variant, a mutation from BA.2.86, first identified in October 2023, after the training cut-off of the AIs used. This success underscores the necessity of RAG for staying current with evolving information, a capability that AI models like GPT-3.5 lack without additional mechanisms. In contrast, ChatGPT Pro, equipped with GPT-4 and a searchable account, can also recognize this new knowledge. This demonstrates the power of combining advanced LLMs with retrieval-augmented methods to remain abreast of rapidly evolving global situations.
Therefore, we can improve our final equation as of following:
$$\text{K} = \text{argmax}_{D, M, R} f(\text{g}(D, M), \text{R})$$
This equation illustrates how we can maximize the quality of the output (knowledge that has been processed), or concurrently, reduce hallucination in AI systems through various methods. It encapsulates the principle of optimizing the inputs and processes involved in AI knowledge formation: maximizing the quality of data (D) to ensure accuracy and relevance, refining the cognitive architecture (M) for effective data processing and interpretation, and aligning closely with external reality (R) for truthfulness and real-world applicability. This continuous optimization leads to the generation of high-quality, reliable knowledge (K), minimizing the discrepancies and errors often termed as 'hallucinations' in AI outputs. The equation represents a holistic approach to enhancing AI systems, balancing the intricate interplay between data quality, algorithmic sophistication, and real-world alignment.